
How Smart Imputation and Removal Can Save Your Machine Learning Models
Discover the secrets behind handling missing data without wrecking your predictions. Learn simple yet powerful techniques that data pros use every day!

Handling missing data is one of the most critical steps in data preprocessing that can make or break your machine learning model.
Whether you’re working with customer surveys, healthcare records, or e-commerce data, chances are you’ll encounter missing values.
Ignoring these gaps or handling them poorly can lead to misleading insights and weak predictive power.
Let’s explore the two main strategies—imputation and removal—using clear examples and practical tips to boost your data science skills.
Why Missing Data Matters?
Imagine you’re building a churn prediction model for a subscription service. If data about user activity or demographics is missing, the model’s decisions become unreliable.
Fixing missing values properly is like patching holes in a boat before setting sail—it prevents critical leaks in your analysis.
But first, understanding why data might be missing shapes your approach:
MCAR (Missing Completely at Random): Missing values occur randomly. For example, a survey participant accidentally skips a question.
MAR (Missing at Random): Missingness depends on other known variables. For instance, younger users might be less likely to report income.
MNAR (Missing Not at Random): Missingness depends on the missing value itself, like high earners avoiding income disclosure.
1. Removal: The Quick Fix
Removing missing data is the simplest way to proceed:
Listwise Deletion: Drop any row with missing values.
Column Removal: Remove features with too many missing entries.
This approach works if missing data is scarce and random, avoiding bias. But beware—removing too much data can shrink your dataset, undermining model training.
For example, if 10% of your customer dataset has missing age info, dropping those rows cuts your training pool with no guarantee the missingness was random.
2. Imputation: Filling the Gaps
Imputation replaces missing values with smart guesses based on existing data. Picking the right method depends on the context and amount of missingness.
Simple Imputation Techniques:
Mean Imputation: For a missing age, substitute the average across the dataset.
Median Imputation: Useful if the data has extreme values or outliers.
Mode Imputation: For missing categories like “gender,” fill with the most frequent class.
While easy, simple approaches can distort data distributions and relationships between variables.
Advanced Imputation Techniques:
K-Nearest Neighbors (KNN): Replaces a missing value with the average of nearest similar samples.
Multiple Imputation: Creates multiple complete datasets with estimated values, analyzes them separately, and averages results for robust conclusions.
Regression Imputation: Predicts missing values using regression models on other features.
These methods capture complex patterns and usually deliver better results, though they require more computation and care to avoid overfitting.
When to Choose Imputation or Removal?
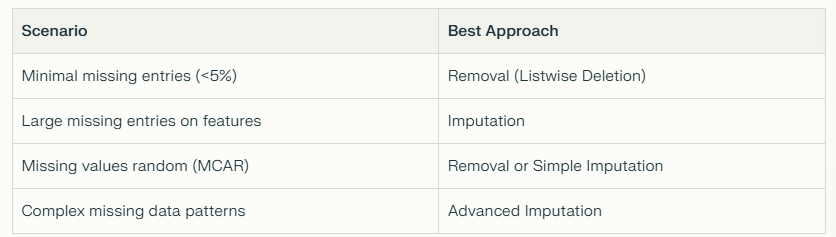
Tips and Tricks:
Analyze missingness patterns visually before deciding.
Avoid “leaking” information: fit scalers and imputers on training data only.
Consider creating missingness indicators: features that mark whether data was missing, helping the model learn missingness patterns.
Test different imputation methods and validate impact on your model’s accuracy.
Summary
Removal is simple but risks losing info and bias.
Imputation fills missing gaps preserving data volume and relationships.
For small, random missingness, removal can suffice.
For complex or large-scale missing data, imputation, especially advanced methods, is superior.
Handling missing data wisely builds trust and accuracy in your models.
Treat missing data like a puzzle to solve, not a barrier. With smart imputation and thoughtful removal, you build machine learning models that perform better and tell clearer stories.
If this piece made you pause, reflect, or even jot something down for later, that’s the kind of work I love creating.
You can also support my writing through Buy Me a Coffee — only if you want to and can. And if you’d like to keep the conversation going, you’ll always find me on LinkedIn.
Thank you for reading.